Open vSwitch kernel moduleの実装からLinux kernel network stackに寄り道する
Posted on 2014/05/21(Wed) 20:25 in technical
さまり
Open vSwitch kernel moduleの実装を読みつつ、よくわかんないので 結果的にLinux kernelも読みに行くことになってしまったメモです。
Open vSwitchでVXLANを使ってみたりしたけど、VLANと一緒に使ったときの扱いとか、 細かいところを気にするとやっぱりコード読んだ方が良いんじゃないかと思ったので、 処理経路の整理も兼ねてコードを追ってみることにしたのです。
およそ、この辺に触れる。
- Linux-kernel-3.11のNetwork stack
- dev.c
- ip_input.c
- ip_output.c
- udp.c
- openvswitch-2.1.0のKernel module
大体この人の後追い。
http://blog.ecchu.jp/daisuke/ja/posts/2013/05/ovs-1_10_0-reading-2.html
最初に結論
とりあえず、こんな感じのダイアグラムになった。
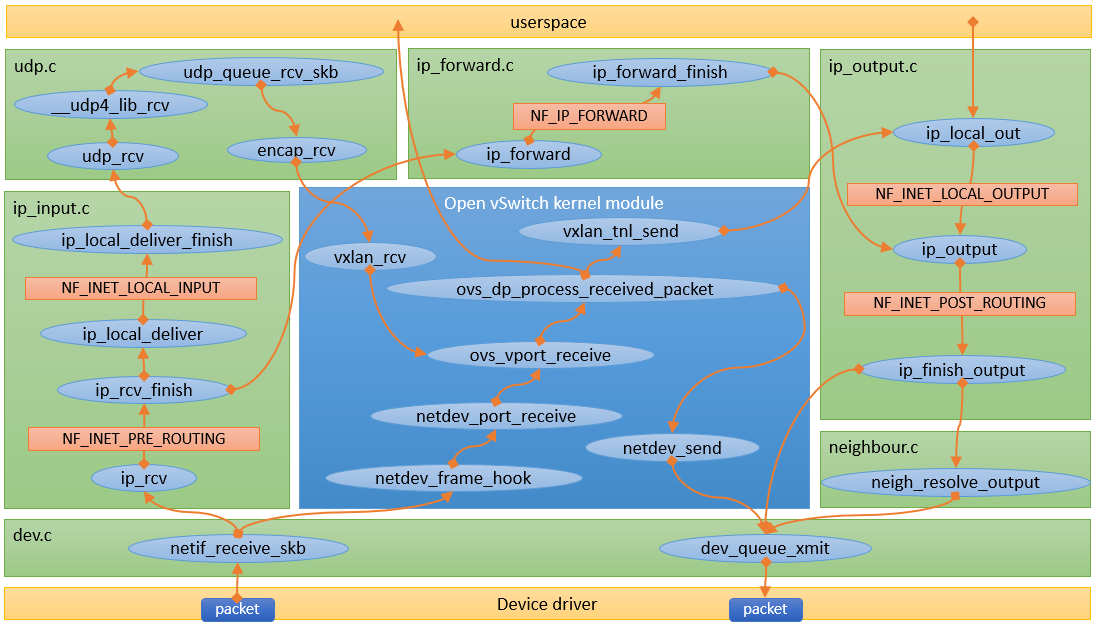
とっかかり
Open vSwtichはLinuxにはKernel moduleを提供していて、 こいつがフローマッチングとかパケット転送とかカプセル化とかその辺の処理をしてくれる。
こういうアーキテクチャになっているらしい。:
_
| +-------------------+
| | ovs-vswitchd |<-->ovsdb-server
| +-------------------+
| | ofproto |<-->OpenFlow controllers
| +--------+-+--------+ _
| | netdev | |ofproto-| |
userspace | +--------+ | dpif | |
| | netdev | +--------+ |
| |provider| | dpif | |
| +---||---+ +--------+ |
| || | dpif | | implementation of
| || |provider| | ofproto provider
|_ || +---||---+ |
|| || |
_ +---||-----+---||---+ |
| | |datapath| |
kernel | | +--------+ _|
| | |
|_ +--------||---------+
||
physical
NIC
参照 : https://github.com/horms/openvswitch/blob/master/PORTING
Linux kernelモジュールを使って、datapathがkernel内で完結している場合は、 userspaceへの余計なコピーも無くて速そうだなぁ、となんとなく思う。
どうせuserspace側は設定とかフローの設定コマンドだろうし、 userspaceのことは忘れてkernel moduleだけ見に行けばいいんじゃないかな、 ということでKernel見に行くモードになる。
何から見ようか
さて、やはりパケット受信部分からスタートしたいところだが、そもそもopenvswitchのkernel moduleにフレームデータが渡されるのは何時なんだという話になる。
とりあえずバージョンとか決めておかないといけないので、この辺をチョイスすることにした。(このことが後に事を難解にするとも知らずn(ry
- Ubuntu 12.04.4(Linux kernel-3.11)
- openvswitch-2.1.0
仮想SWの作成だけだと、LOCALなポートがあるだけだし、そこはとりあえず放置。
まずは"linux network stack"で画像検索して、フレーム受信時のひっかけ先を探した結果、"netif_receive_skb"という関数を見つける。
とりあえずはこの辺から見ていく。
Linux kernel(v3.11)からOpen vSwitch kernel moduleまで
netif_receive_skbを検索して軽く追ってみる。
http://lxr.free-electrons.com/ident?v=3.11;i=netif_receive_skb
-> netif_receive_skb() http://lxr.free-electrons.com/source/net/core/dev.c?v=3.11#L3668
-> __netif_receive_skb() http://lxr.free-electrons.com/source/net/core/dev.c?v=3.11#L3628
-> __netif_receive_skb_core() http://lxr.free-electrons.com/source/net/core/dev.c?v=3.11#L3480
軽く眺めて見た感じ、rx_handlerの辺り( http://lxr.free-electrons.com/source/net/core/dev.c?v=3.11#L3562 )がそれっぽい。
早速grepしてみる。:
$ grep -n "rx_handler" datapath/* grep: datapath/linux: Is a directory datapath/vport-netdev.c:41:static rx_handler_result_t netdev_frame_hook(struct sk_buff **pskb) datapath/vport-netdev.c:130: err = netdev_rx_handler_register(netdev_vport->dev, netdev_frame_hook, datapath/vport-netdev.c:168: netdev_rx_handler_unregister(netdev_vport->dev); datapath/vport-netdev.c:261: if (likely(rcu_access_pointer(dev->rx_handler) == netdev_frame_hook)) datapath/vport-netdev.c:266: return (struct vport *)rcu_dereference_rtnl(dev->rx_handler_data);
datapath/vport-netdev.c:netdev_create()からnetdev_rx_handler_registerを呼んでnetdev_frame_hookを登録しておいて、フレーム受信時は:
dev.c:netif_receive_skb()
-> dev.c:__netif_receive_skb()
-> dev.c:__netif_receive_skb_core()
-> dev.c:rx_handler(&skb)
-> datapath/vport-netdev.c:netdev_frame_hook()
という感じになれば辻褄が合いそうだ。
まずこの「netdev_rx_handler_register() is 何」ということで調べる。
http://lxr.free-electrons.com/ident?v=3.11&i=netdev_rx_handler_register
-> http://lxr.free-electrons.com/source/net/core/dev.c?v=3.11#L3423
つまり、netdev_rx_handler_register() is rcu_assign_pointer() for rx_handlerということだな?
成程、分からん(様式美)
RCU自体についてはここでは棚上げにするけど、dev->rx_handlerに関数ポインタを関連付けて、 デバイス毎の受信ハンドラをRCUに管理させるという理解で終わらせる。
ということは、登録作業は大体こんな感じ:
datapath/vport-netdev.c:netdev_create()
-> datapath/vport-netdev.c:netdev_rx_handler_register()
-> dev.c:netdev_rx_handler_register()
-> あとはRCUの関数ネスト
netdev_create()はこんな感じで入っているので
const struct vport_ops ovs_netdev_vport_ops = {
.type = OVS_VPORT_TYPE_NETDEV,
.create = netdev_create,
.destroy = netdev_destroy,
.get_name = ovs_netdev_get_name,
.send = netdev_send,
};
他のポートと同様に、createされたときに呼ばれるようになっているんでしょう。後回しにしよう。
ついでに、"netdev_rx_handler_register"について検索すると、検索結果の下の方にnet/bridge/br_if.cも出てくるのでついでに見てみると、 openvswitchとほぼ同様の登録方法がとられていることが分かる。
http://lxr.free-electrons.com/ident?v=3.11&i=netdev_rx_handler_register
-> http://lxr.free-electrons.com/source/net/bridge/br_if.c?v=3.11#L373
と、ここまでで受信フレームのhook登録と入口が見えてくる。
Linux kernel(2.6.34)に寄り道
少し古いコード(2.6.34)の同じような場所を見に行く。
skb = handle_bridge(skb, &pt_prev, &ret, orig_dev); http://lxr.free-electrons.com/source/net/core/dev.c?v=2.6.34#L2552
-> handle_bridge() http://lxr.free-electrons.com/source/net/core/dev.c?v=2.6.34#L2333
-> return br_handle_frame_hook(port, skb);
同じ時代のbr.cも見てみると、br_handle_frame_hook = br_handle_frame;とかやってる。
http://lxr.free-electrons.com/source/net/bridge/br.c?v=2.6.34#L66
で、br_handle_frameはこれ。
http://lxr.free-electrons.com/source/net/bridge/br_input.c?v=2.6.34#L136
まさにこの辺でhookしているというのが分かり易い名前だ...
寄り道終わり。
Open vSwitch kernel moduleの中
さて、個人的には転送の処理自体はモジュールの中で好きにやってくれという気分なので、 割とどうでもいいのだが、中を通らないと外に抜けられないし、しょうがない。
入口であるdatapath/vport-netdev.c:netdev_frame_hook()から掘っていけばいいわけじゃろ?:
datapath/vport-netdev.c:netdev_frame_hook()
-> datapath/vport-netdev.c:netdev_port_receive()
-> datapath/vport.c:ovs_vport_receive()
-> datapath/datapath.c:ovs_dp_process_received_packet()
// パース
-> datapath/flow.c:ovs_flow_extract()
// フローテーブルのルックアップ処理
-> datapath/flow_table.c:ovs_flow_tbl_lookup_stats()
-> datapath/flow_table.c:masked_flow_lookup()
// アクション
-> datapath/actions.c:ovs_execute_actions()
-> datapath/actions.c:do_execute_actions()
// ポートへの出力
-> datapath/actions.c:do_output()
-> datapath/vport.c:ovs_vport_send()
-> vport->ops->send(vport, skb)
この辺は細かいことを無視すれば、大体こうなってるんですねー、という感じ。
vport->ops->sendについては、".send"でgrepすればいいのであろ?:
$ grep "\.send" datapath/* grep: datapath/linux: Is a directory datapath/vport-gre.c: .send = gre_send, datapath/vport-gre.c: .send = gre64_send, datapath/vport-internal_dev.c: .send = internal_dev_recv, datapath/vport-lisp.c: .send = lisp_send, datapath/vport-netdev.c: .send = netdev_send, datapath/vport-vxlan.c: .send = vxlan_tnl_send,
あとはまぁ、対象になってる関数を読みに行けば、基本的にはそこでの処理が書いてあるはずだ。
send関数は、とりあえずトンネルインタフェースと通常のインタフェースを抑えておけばいいんじゃないだろうか。
userspaceに上げる時はどうかなぁ。
openvswitchには内部用のフローエントリがあるからそこに引っかかってるだけだし、棚上げですね。:
# ovs-ofctl dump-flows br0 NXST_FLOW reply (xid=0x4): cookie=0x0, duration=142.341s, table=0, n_packets=8, n_bytes=648, idle_age=1414, priority=0 actions=NORMAL # ovs-appctl bridge/dump-flows br0 duration=140s, n_packets=8, n_bytes=648, priority=0,actions=NORMAL table_id=254, duration=140s, n_packets=0, n_bytes=0, priority=0,reg0=0x3,actions=drop table_id=254, duration=140s, n_packets=0, n_bytes=0, priority=0,reg0=0x1,actions=controller(reason=no_match) table_id=254, duration=140s, n_packets=0, n_bytes=0, priority=0,reg0=0x2,actions=drop
物理インタフェースから出ていくとき
物理とは言ったが、VLANインタフェースも似たようなもんじゃぞ。VLANインタフェース(物理)とか意味わからんからやめよう。
Ethernetインタフェースと言った方が正確かもしれない。
ともあれ、開始地点はdatapath/vport-netdev.c:netdev_send()からです。:
datapath/vport-netdev.c:netdev_send() -> dev_queue_xmit()
終わった(完)
dev_queue_xmit()から先はLinux kernelの仕事。
dev.c:dev_queue_xmit()はここにある。
http://lxr.free-electrons.com/source/net/core/dev.c?v=3.11#L2803
dev_queue_xmit()はnetif_receive_skb()と同じくらいの粒度だし、この辺で止めておこう。
トンネルインタフェースから出ていくとき
次はOpen vSwitchがカプセル化する場合のトンネルインタフェース。
VXLANをベースにすると、vxlan_tnl_send()からですね。:
vport-vxlan.c:vxlan_tnl_send()
// ここで経路のルックアップがある
-> datapath/compat.h:find_route()
// ここでVXLANヘッダが付く
-> datapath/linux/compat/vxlan.c:vxlan_xmit_skb()
// トンネルの共通処理
-> datapath/linux/compat/ip_tunnels_core.c:iptunnel_xmit()
-> ip_local_out()
おしまい(完)
net/ipv4/ip_output.c:ip_local_outはこの辺。
http://lxr.free-electrons.com/source/net/ipv4/ip_output.c?v=3.11#L104
net/ipv4/ip_output.c:ip_local_out() -> net/ipv4/ip_output.c:__ip_local_out() -> nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, skb, NULL, skb_dst(skb)->dev, dst_output);
となるので、ip_local_out()から先はLinux kernelの仕事だけど、NF_INET_LOCAL_OUTがすぐ後に来るから、カプセル化した後はIPFilterにひっかかる。
逆に、入力時点ではrx_handlerからOpen vSwitch kernel moduleの領域に入ってしまうので、IPFilterの入る余地は無さそうだった。
トンネルインタフェースから入って来るとき
IPFilterの話が出たので、Open vSwitchのVXLANインタフェースで受信する場合の経路も見ていきたい。
さっき見たときは、受信経路はこんな感じだった(前略):
dev.c:rx_handler(&skb) -> datapath/vport-netdev.c:netdev_frame_hook()
これは、netdev_create()したときにnetdev_rx_handler_register()してあるからだ。
VXLANインタフェースの場合はどうか。
vport-netdev.cがこうで
const struct vport_ops ovs_netdev_vport_ops = {
.type = OVS_VPORT_TYPE_NETDEV,
.create = netdev_create,
.destroy = netdev_destroy,
.get_name = ovs_netdev_get_name,
.send = netdev_send,
};
vport-vxlan.cがこうだから
const struct vport_ops ovs_vxlan_vport_ops = {
.type = OVS_VPORT_TYPE_VXLAN,
.create = vxlan_tnl_create,
.destroy = vxlan_tnl_destroy,
.get_name = vxlan_get_name,
.get_options = vxlan_get_options,
.send = vxlan_tnl_send,
};
vxlan_tnl_create()をざっと眺める。
普通に考えたら、
vs = vxlan_sock_add(net, htons(dst_port), vxlan_rcv, vport, true);
この辺が怪しい。ので、追ってみる。:
datapath/vport-vxlan.c:vxlan_sock_add() -> datapath/linux/compat/vxlan.c:vxlan_sock_add() -> datapath/linux/compat/vxlan.c:vxlan_socket_create()
vxlan_socket_create()では、:
1. rc = sock_create_kern(AF_INET, SOCK_DGRAM, IPPROTO_UDP, &vs->sock); 2. rc = kernel_bind(vs->sock, (struct sockaddr *) &vxlan_addr, sizeof(vxlan_addr)); 3. udp_sk(sk)->encap_rcv = vxlan_udp_encap_recv;
辺りが本体っぽい。
sock_create_kern()はUDPのソケットの生成で、vxlan_addrにIPとVXLANのポート番号が入ってるからkernel_bind()でアドレスとマッピングして、 udp_sk(sk)->encap_rcvでvxlan_udp_encap_recv()が呼ばれるようにしているということだな。
Kernel socketの作り方のお作法がよくわかんないけど、そこは棚上げ。
とにかく、今度はudp_sk(sk)->encap_rcvが呼ばれるところまで、UDPパケットの気持ちになってkernelの中を泳げばいいわけだ。
それにしても、udp_encap_enable()なんて関数があるんですねぇ。 http://lxr.free-electrons.com/source/net/ipv4/udp.c#L1450
で、どうなっているかというと:
net/core/dev.c:netif_receive_skb()
-> net/core/dev.c:__netif_receive_skb()
-> net/core/dev.c:__netif_receive_skb_core()
-> net/core/dev.c:deliver_skb()
-> pt_prev->func()
func()は、net/ipv4/af_inet.cに定義があるようだ。
http://lxr.free-electrons.com/source/net/ipv4/af_inet.c?v=3.11#L1679
で、そこから再度:
net/ipv4/ip_input.c:ip_rcv()
-> net/ipv4/ip_input.c:NF_HOOK(ip_rcv_finish)
-> net/ipv4/ip_input.c:ip_rcv_finish()
-> net/ipv4/route.c:ip_route_input_noref()
-> net/ipv4/route.c:ip_route_input_slow()
rth->dst.input= ip_local_deliver;をセットして帰ってくる。
-> net/dst.h:dst_input()
-> net/ipv4/ip_input.c:ip_local_deliver()
-> net/ipv4/ip_input.c:NF_HOOK(ip_local_deliver_finish)
-> net/ipv4/ip_input.c:ip_local_deliver_finish()
-> ipprot->handler(skb);
ipprot->handler()は、net/ipv4/af_inet.cに定義があるようだ。
http://lxr.free-electrons.com/source/net/ipv4/af_inet.c?v=3.11#L1562
で、そこからさらに:
net/ipv4/udp.c:udp_rcv()
-> net/ipv4/udp.c:__udp4_lib_rcv()
-> net/ipv4/udp.c:udp_queue_rcv_skb()
-> encap_rcv = ACCESS_ONCE(up->encap_rcv);
-> ret = encap_rcv(sk, skb);
ここっぽい。
さっきVXLANポートを作るときに、udp_sk(sk)->encap_rcv = vxlan_udp_encap_recv;ってしておいたのがここで引っかかる。
後はopenvswitchの領域に入るんだろう。サクサク眺める。:
datapath/linux/compat/vxlan.c:vxlan_udp_encap_recv() // ここでVXLANヘッダを外す -> datapath/linux/compat/ip_tunnels_core.c:iptunnel_pull_header() -> vs->rcv(vs, skb, vxh->vx_vni);
vs->rcvってどこで作ったっけかな。もう1回VXLANトンネルを作ったところを見に行く。:
vs->rcv = rcv;
<- datapath/linux/compat/vxlan.c:vxlan_socket_create()
<- datapath/linux/compat/vxlan.c:vxlan_sock_add()
<- vs = vxlan_sock_add(net, htons(dst_port), vxlan_rcv, vport, true);
<- datapath/vport-vxlan.c:vxlan_tnl_create()
つまりvs->rcv()でvxlan_rcv()が呼ばれるので、そこから再スタート:
datapath/vport-vxlan.c:vxlan_rcv() -> datapath/vport.c:ovs_vport_receive()
netdevで受信した場合の経路を再度見ると:
datapath/vport-netdev.c:netdev_frame_hook() -> datapath/vport-netdev.c:netdev_port_receive() -> datapath/vport.c:ovs_vport_receive()
なので、パケットデータは多少違うものの、そこから先は同じ処理経路を通ることになる。
クールダウン
大枠としてはこんな感じだろうか。
かなり乱暴な読み方しかできないので、詳細については全部棚上げになってしまうのが残念。
こう見ると、やっぱりOpen vSwtich自体が自律動作する実装(Multicast VXLANのような論理ポートとか)はコンセプトと合わないなーと思う。
それにしても、他の部分の実装はあまり追う気になれませんねぇ。