python + dpkt で pcap解析 - 2.パケット生成と保存
Posted on 2012/05/13(Sun) 02:35 in technical
前回(python + dpkt -> pcap解析 – 1.読み込みから解析開始まで) に引き続き、dpktの使い方を見ていく。
次はこの辺りか。
- パケットの生成と保存
- 読み込んだパケットをフロー分類して別のファイルに保存
既に解析ではないね...うん...
ソース見れば分かる人はBitbucketへどうぞ。
まず「パケット生成と保存」をしてみる。
パケット生成の基本は、 dpktのフロントページ に書いてある通りだ。
今回は、SYN Flood辺りを想定して、SYNパケットを沢山作ってそれをpcapファイルに出力してみる。
ステップは簡単だ。
- Step.1 : dpkt(とsocket)のimport
- Step.2 : Ethernet, IPv4, TCPの各ヘッダをオブジェクトとして生成
- Step.3 : pcap(libpcap)形式でファイルを開く
- Step.4 : 送信元アドレスを増加させながらpcapファイルに書き込む
# -*- coding: utf-8 -*-
#!/usr/bin/env python
#
# Step.1
#
import dpkt
import socket
def main():
#
# Step.2
#
# Ethernet header
eth = dpkt.ethernet.Ethernet()
eth.src = '\x00\x00\x01\x00\x00\x01'
eth.dst = '\x00\x00\x01\x00\x00\x02'
eth.type = dpkt.ethernet.ETH_TYPE_IP
# IP header
ip = dpkt.ip.IP()
ip.dst = socket.inet_aton('172.16.0.1')
ip.p = dpkt.ip.IP_PROTO_TCP
# TCP header
tcp = dpkt.tcp.TCP()
tcp.sport = 60001
tcp.dport = 80
tcp.flags = dpkt.tcp.TH_SYN
#
# Step.3
#
# Open write pcapfile
output_pcapfile = dpkt.pcap.Writer(open(__file__+'.pcap','wb'))
#
# Step.4
#
packet_count = 0
while (packet_count<100):
packet_count += 1
tcp.sum = 0
ip.data = tcp
ip.src = socket.inet_aton( '192.168.0.' + str(packet_count) )
ip.len = len(str(ip))
ip.sum = 0
eth.data = ip
output_pcapfile.writepkt(eth,packet_count)
output_pcapfile.close()
if __name__ == '__main__':
main()
特に面白みも無いコードだが、簡単にTCPのSYNパケットが100個程生成されたことだろう。
敢えて注意すべき点を挙げるとすると、tcp.sumとip.sumに明示的に0を指定していることだろうか。
output_pcapfile.writepkt(eth,packet_count)の時点(正確に言うと内部でオブジェクトがstr参照された時点)で、チェックサムの再計算が走るのだが、チェックサムの値が0でなければ再計算は行われない。
最初のオブジェクト生成段階では、0で初期化されるので問題ないが、その後使いまわすと再計算されず、ずっと同じ値になってしまう。とは言え、これはあくまでdpktライブラリの仕様。
ネットワーク的に考えれば、Ethernetフレームの最小長は64Byte(FCS込)になることを考慮すべきだし(デバイスを通じて実際に出力される場合は考える必要はない)、プログラム的に考えれば、送信元IPの増やし方はこのままでは255を超えた場合、例外を吐くことは想像に難くない。
でも、サンプルとして軽く流そう。
次に、「読み込んだパケットをフロー分類して別のファイルに保存」してみる。
例によってwireshark wikiから、 Some Skype, IRC and DNS traffic. を拝借しよう。(拡張子は.capだけど、libpcap形式だからdpktでも認識できる)
前回作成したサンプルコードと組み合わせて、IPフロー(例によって3-tuple)毎に別々のpcapファイルに保存してみよう。
少し読みにくいかもしれないが...。
- Step.1 : dpkt(とsocket)のimport
- Step.2 : 読み込み対象のファイルを決定し、ファイルを開く
- Step.3 :
- packet_count(パケットの数)
- flow(送受信IPとフローIDとのマップ)
- flow_no(IPフローID)
- output_pcap(保存先pcapファイルオブジェクトの一覧)
- Step.4 : パケットのデコード
- Step.5 : 送受信IPアドレスからフロー識別文字列を生成
- Step.6 : 登録済みフローでない場合、当該フロー用の保存先pcapファイルオブジェクトを一覧に追加
- Step.7 : 登録済みフローの保存先へパケットを保存
- Step.4~7を繰り返し
SkypeIRC.capを使用した場合は、IPフローで183フローなので、ドバーっと出力される。
# -*- coding: utf-8 -*-
#!/usr/bin/env python
#
# Step.1
#
import dpkt
import socket
def main():
#
# Step.2
#
input_pcap = u'C:\\dev\\pcap\\SkypeIRC.cap'
pcr = dpkt.pcap.Reader(open(input_pcap,'rb'))
#
# Step.3
#
packet_count = 0
flow = {}
flow_no = 0
output_pcap = []
for ts,buf in pcr:
#
# Step.4
#
packet_count += 1
try:
eth = dpkt.ethernet.Ethernet(buf)
except:
print 'Fail parse FrameNo:', packet_count, '. skipped.'
continue
if type(eth.data) == dpkt.ip.IP:
#
# Step.5
#
ip = eth.data
src = socket.inet_ntoa(ip.src)
dst = socket.inet_ntoa(ip.dst)
up_stream = src + " to " + dst
down_stream = dst + " to " + src
#
# Step.6
#
if not flow.has_key(up_stream) and not flow.has_key(down_stream):
fp = open(input_pcap+'_flow-'+str(flow_no+1)+'.pcap','wb')
output_pcap.append(dpkt.pcap.Writer(fp))
flow[up_stream] = flow_no
flow_no += 1
#
# Step.7
#
if flow.has_key(up_stream):
output_pcap[flow[up_stream]].writepkt(buf,ts)
if flow.has_key(down_stream):
output_pcap[flow[down_stream]].writepkt(buf,ts)
for pcw in output_pcap:
pcw.close
if __name__ == '__main__':
main()
こんな感じに。
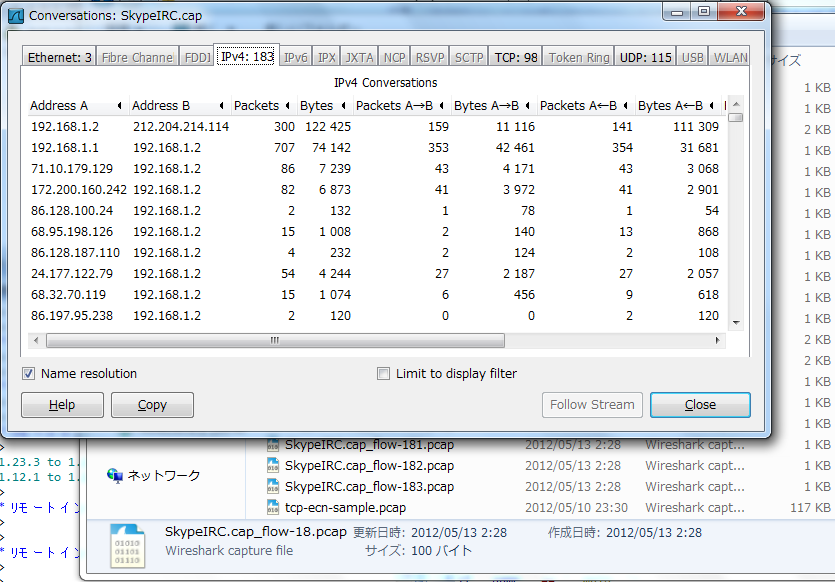
DNSから派生したと想定されるTCPセッションとあわせて抽出したり、1つのGETから派生したと想定されるHTTPセッションとあわせて抽出したり、SIPから派生したRTPフロー別に抽出したり...と、用途は様々かと思う。
とりあえずパケット生成から保存まで。
これで、一通りのことは出来ると思うんだが...どうだろう?